Deep Learning Final Project
This semester, I took a contemporary topics course on deep learning. For the final project, I decided to learn more about multi-task learning (MTL). The final report can be found here, and the code here.
Intro
This project was an exploration of different hard-parameter sharing architectures, and their impact on classification tasks. The end goal of this project was to develop an intuition for the effects hard-parameter sharing, and to learn how to build networks with multiple inputs and outputs.
CIFAR100
The CIFAR100 dataset consists of 100 classes of images, which are grouped into 20 super classes. These can be thought of as fine and coarse grain labels. The data consists of 500 training images, and 100 test images for each fine class. Each image has exactly one fine label and one coarse label. The images in the CIFAR100 dataset are 32x32 RGB (three channel) images, making the network input shape: $(32, 32, 3)$.
Network Architectures
1) Independent networks (the control architecture)
input_image --> conv_layers --> fc_layers --> fine_label
input_image --> conv_layers --> fc_layers --> coarse_label2) Hard parameter sharing in convolutional layers
/--> fc_layers --> fine_label
input_image --> conv_layers
\--> fc_layers --> coarse_label3) Using coarse label output as weights
input_image ----> conv_layers ----> fc_layers_1
\
concat -> fc_layers_2 -> fine_label
/
input_image -> conv_layers -> fc_layers -> coarse_label4) Using fine label output as weights
input_image ----> conv_layers ----> fc_layers_1
\
concat -> fc_layers_2 -> coarse_label
/
input_image -> conv_layers -> fc_layers -> fine_label5) Combination of 2 & 3
/ -------------> fc_layers_1
/ \
input_image -> conv_layers concat -> fc_layers_2 -> fine_label
\ /
\-> fc_layers -> coarse_label6) Combination of 2 & 4
/ -------------> fc_layers_1
/ \
input_image -> conv_layers concat -> fc_layers_2 -> coarse_label
\ /
\-> fc_layers -> fine_labelResults
After training each model with the same hyper-parameters for 100 epochs, I obtained the following results:
Table of Metrics at Last Interation (Epoch 100)
| Model | Fine Loss | Coarse Loss | Fine Accuracy | Coarse Accuracy |
|---|---|---|---|---|
| Independent | 1.96 | 1.15 | 48.86% | 64.16% |
| Shared Convolutions | 1.94 | 1.16 | 49.09% | 64.20% |
| Reuse Coarse Labels | 1.83 | 1.21 | 51.50% | 62.29% |
| Reuse Fine Labels | 1.95 | 1.07 | 49.14% | 68.38% |
| Shared Reuse Coarse | 1.86 | 1.16 | 50.34% | 63.91% |
| Shared Reuse Fine | 1.84 | 1.06 | 50.91% | 67.11% |
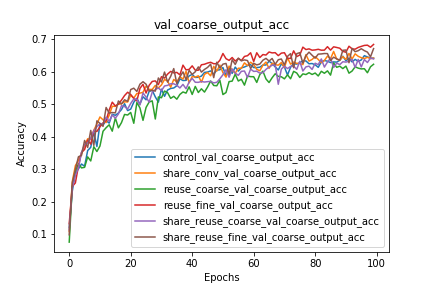
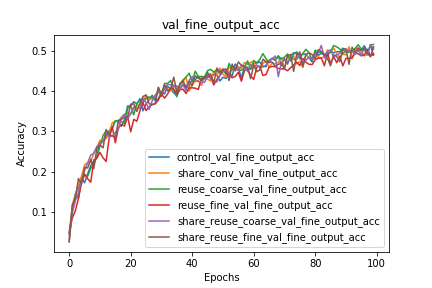
Coarse and Fine Classification Accuracy
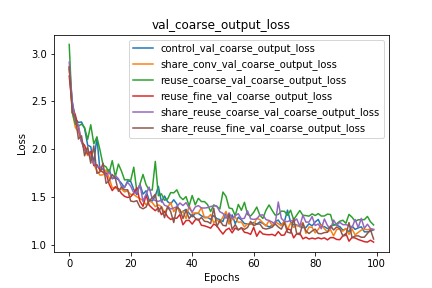
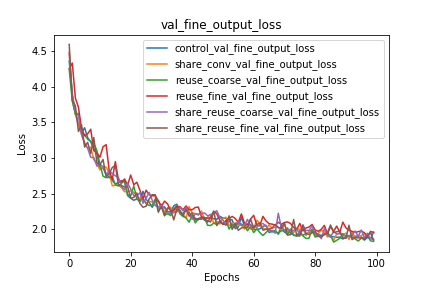
Coarse and Fine Classification Loss
Conclusions & Lessons Learned
We can observe that the reuse of coarse/fine labels significantly benefits the performance of the network on the other task that is not being reused. We should additionally note that the architectures that reuse the coarse labels perform worse on coarse label prediction than the control network. I hypothesize that this is because the error $w.r.t.$ the fine labels is propagated through the layers that predict the coarse label, and that these gradients, while improving fine label classification, slow down and even hurt the coarse label classification.
If I were to redo this experiment, I would train each network until the validation loss started to diverge (not a fixed number of epochs). This would allow me to better assess how these hard-parameter sharing techniques impact convergence rate. I would also train all of these networks multiple times to get average performances for each network. Lastly, I think it would be interesting to examine the impact of convolutional layer weight sharing on transfer learning. I would expect that the weights from shared layers would be more robust and effective for transfer learning than either task independently.